

It is difficult to follow all the new developments in AI. How can you discriminate between fundamental technology here to stay, and the hype? How to make sure that you are not missing important developments? The goal of this article is to provide a short summary, presented as a glossary. I focus on recent, well-established methods and architecture.
I do not cover the different types of deep neural networks, loss functions, or gradient descent methods: in the end, these are the core components of many modern techniques, but they have a long history and are well documented. Instead, I focus on new trends and emerging concepts such as RAG, LangChain, embeddings, diffusion, and so on. Some may be quite old (embeddings), but have gained considerable popularity in recent times, due to widespread use in new ground-breaking applications such as GPT.
New Trends
The landscape evolves in two opposite directions. On one side, well established GenAI companies implement neural networks with trillions of parameters, growing more and more in size, using considerable amounts of GPU, and very expensive. People working on these products believe that the easiest fix to current problems is to use the same tools, but with bigger training sets. Afterall, it also generates more revenue. And indeed, it can solve some sampling issues and deliver better results. There is some emphasis on faster implementations, but speed and especially size, are not top priorities. In short, more brute force is key to optimization.
On the other side, new startups including myself focus on specialization. The goal is to extract as much useful data as you can from much smaller, carefully selected training sets, to deliver highly relevant results to specific audiences. Afterall, there is no best evaluation metric: depending on whether you are a layman or an expert, your criteria to assess quality are very different, even opposite. In many cases, the end users are looking for solutions to deal with their small internal repositories and relatively small number of users. More and more companies are concerned with costs and ROI on GenAI initiatives. Thus, in my opinion, this approach has more long-term potential.
Still, even with specialization, you can process the entire human knowledge — the whole Internet — with a fraction of what OpenAI needs (much less than one terabyte), much faster, with better results, even without neural networks: in many instances, much faster algorithms can do the job, and it can do it better, for instance by reconstructing and leveraging taxonomies. One potential architecture consists of multiple specialized LLMs or sub-LLMs, one per top category. Each one has its own set of tables and embeddings. The cost is dramatically lower, and the results more relevant to the user who can specify categories along with his prompt. If in addition you allow the user to choose the parameters of his liking, you end up with self-tuned LLMs and/or customized output. I discuss some of these new trends in more details, in the next section. It is not limited to LLMs only.
Key Concepts
The list below is in alphabetical order. In many cases, the description highlights how I use the concepts in question in my own open-source technology.
- ANN (Approximate nearest neighbor). Similar to the K-NN algorithm used in supervised classification, but faster and applied to retrieving information in vector databases, such as LLM embeddings stored as vectors. I designed a probabilistic version called pANN, especially useful for model evaluation and improvement, with applications to GenAI, synthetic data, and LLMs. See here.
- Diffusion. Diffusion models use a Markov chain with diffusion steps to slowly add random noise to data and then learn to reverse the diffusion process to construct desired data samples from the noise. The output is usually a dataset or image similar but different from the original ones. Unlike variational autoencoders, diffusion models have high dimensionality in the latent space (latent variables): the same dimension as the original data. Very popular in computer vision and image generation.
- Embedding. In LLMs, embeddings are typically attached to a keyword, paragraph, or element of text; they consist of tokens. The concept has been extended to computer vision, where images are summarized in small dimensions by a number of numerical features (far smaller than the number of pixels). Likewise, in LLMs, tokens are treated as the features in your dataset, especially when embeddings are represented by fixed-size vectors. The dimension is the number of tokens per embedding. See tokens.
- Encoder. An autoencoder is (typically) a neural network to compress and reconstruct unlabeled data. It has two parts: an encoder that compacts the input, and a decoder that reverses the transformation. The original transformer model was an autoencoder with both encoder and decoder. However, OpenAI (GPT) uses only a decoder. Variational autoencoders (VAE) are very popular.
- GAN (generative adversarial network). One of the many types of DNN (deep neural network) architecture. It consists of two DNNs: the generator and the discriminator, competing against each other until reaching an equilibrium. Good at generating synthetic images similar to those in your training set (computer vision). Key components include a loss function, a stochastic gradient descent algorithm such as ADAM to find a local minimum to the loss function, and hyperparameters to fine-tune the results. Not good at synthesizing tabular data, thus the reason I created NoGAN: see here.
- GPT. In case you did not know, GPT stands for Generative Pre-trained Transformer. The main application is LLMs. See Transformer.
- Graph database. My LLMs rely on taxonomies attached to the crawled content. Taxonomies consist of categories, subcategories and so on. When each subcategory has exactly one parent category, you use a tree to represent the structure. Otherwise, you use a graph structure.
- Key-value database. Also known as hash table or dictionary in Python. In my LLMs, embeddings have variable size. I store them as short key-value tables rather than long vectors. Keys are tokens, and a value is the association between a token, and the word attached to the parent embedding.
- LangChain. Available as a Python library or API, it helps you build applications that read data from internal documents and summarize them. It allows you to build customized GPTs, and blend results to user queries or prompts with local information retrieved from your environment, such as internal documentation or PDFs.
- LLaMA. An LLM model that predicts the next word in a word sequence, given previous words. See here how I use them to predict the next DNA subsequence in DNA sequencing. Typically associated to auto-regressive models or Markov chains.
- LLM (large language model). Modern version of NLP (natural language processing) and NLG (natural language generation). Applications include chatbots, sentiment analysis, text summarization, search, and translation.
- Multi-agent system. LLM architecture with multiple specialized LLMs. The input data (a vast repository) is broken down into top categories. Each one has its own LLM, that is, its own embeddings, dictionary, and related tables. Each specialized LLM is sometimes called a simple LLM. See my own version named xLLM, here.
- Multimodal. Any architecture that blends multiple data types: text, videos, sound files, and images. The emphasis is on processing user queries in real-time, to return blended text, images, and so on. For instance, turning text into streaming videos.
- Normalization. Many evaluation metrics take values between 0 and 1 after proper scaling. Likewise, weights attached to tokens in LLM embeddings have a value between -1 and +1. In many algorithms and feature engineering, the input data is usually transformed first (so that each feature has same variance and zero mean), then processed, and finally you apply the inverse transform to the output. These transforms or scaling operations are known as normalization.
- Parameter. This word is mostly used to represent the weights attached to neuron connections in DNNs. Different from hyperparameters. The latter are knobs to fine-tune models. Also different from the concept of parameter in statistical models despite the same spelling.
- RAG (retrieval-augmentation-generation). In LLMs, retrieving data from summary tables (embeddings) to answer a prompt, using additional sources to augment your training set and the summary tables, and then generating output. Generation focuses on answering a user query (prompt), on summarizing a document, or producing some content such as synthesized videos.
- Regularization. Turning a standard optimization problem or DNN into constrained optimization, by adding constraints and corresponding Lagrange multipliers to the loss function. Potential goals: to obtain more robust results, or to deal with overparametrized statistical models and ill-conditioned problems. Example: Lasso regression. Different from normalization.
- Reinforcement learning. A semi-supervised machine learning technique to refine predictive or classification algorithms by rewarding good decisions and penalizing bad ones. Good decisions improve future predictions; you achieve this goal by adding new data to your training set, with labels that work best in cross-validation testing. In my LLMs, I let the user choose the parameters that best suit his needs. This technique leads to self-tuning and/or customized models: the default parameters come from usage.
- Synthetic data. Artificial tabular data with statistical properties (correlations, joint empirical distribution) that mimic those of a real dataset. You use it to augment, balance or anonymize data. Few methods can synthesize outside the range observed in the real data (your training set). I describe how to do it, here. A good metric to assess the quality of synthetic data is the full, multivariate Kolmogorov-Smirnov distance, based on the joint empirical distribution computed both on the real and generated observations. It works both with categorical and numerical features. The word “synthetic data” is also used for generated (artificial) time series, graphs, images, videos and soundtracks in multimodal applications.
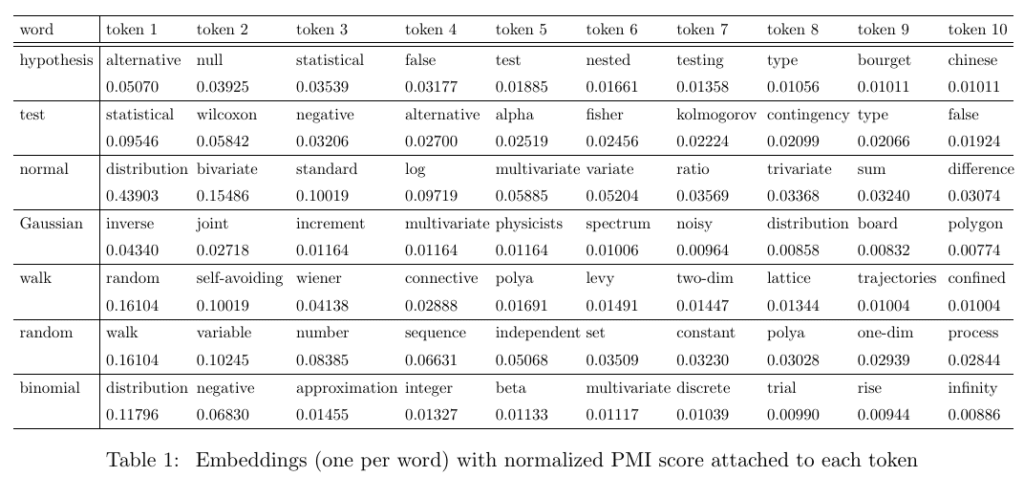
- Token. In LLMs or NLP, a token is a single word; embeddings are vectors, with each component being a token. A word such as “San Francisco” is a single token, not two. In my LLMs, I use double tokens, such as “Gaussian distribution” for terms that are frequently found together. I treat them as ordinary (single) tokens. Also, the value attached to a token is its “correlation” (pointwise mutual information) to the word representing its parent embedding, see picture. But in traditional LLMs, the value is simply the normalized token frequency computed on some text repository.
- Transformer. A transformer model is an algorithm that looks for relationships in sequential data, for instance, words in LLM applications. Sometimes the words are not close to each other, allowing you to detect long-range correlations. It transforms original text into a more compact form and relationships, to facilitate further processing. Embeddings and transformers go together.
- Vector search. A technique combined with feature encoding to quickly retrieve embeddings in LLM summary tables, most similar to prompt-derived embeddings attached to a user query in GPT-like applications. Similar to multivariate “vlookup” in Excel. A popular metric to measure the proximity between two embeddings is the cosine similarity. To accelerate vector search, especially in real-time, you can cache popular embeddings and/or use approximate search such as ANN.
Fuente: www.datasciencecentral.com

