

Continuous Intelligence, DataOps, Data Democratisation, and Data Meshes are the four major trends in data & analytics I’ve been observing lately.
Continuous Intelligence, DataOps, Data Democratisation, and Data Meshes are the four major trends in data & analytics I’ve been observing lately. All of them could become relevant to your business in 2020–21, not because they are the “latest thing” but because there are three major underlying forces pushing those trends forward. And they will come to you in one form or the other.
In this article I will explain:
– What the three forces are that will define analytics strategies in the decade to come.
– What the four trends are that currently emerged from these three forces, that will be relevant in 2020–21.
– What the trends are in some detail with links to resources explaining them far better than I ever could.
Let’s get into the three forces and four trends that will disrupt your analytics strategy!
Trend Overview
I’ve again and again stumbled upon exactly four trends that I believe will become relevant to almost everybody in analytics in 2020–21. These four trends are
– Data Meshes: Data not as a byproduct, but as an actual product. Ownership in producing teams. A concept introduced by ThoughtWorks.
– Data Democratisation: Access to lots of data for everyone in a company, including no-technical employees, used for instance at AirBnB (with adoption rates close to 50%).
– Continuous Intelligence: Automatic near-real-time decision support & making via machine learning and lots of continuous data ingesting & crunching.
– DataOps: Focus on delivering value with data and introducing the now common software engineerings practices like continuous integration (CI) & continuous delivery (CD) and lots more into the data pipeline.
But why will those four trends become so important? I feel they will because there are three major forces pushing those trends forward.
The Underlying Forces Pushing These Trends
The underlying forces that push those trends will, as far as I can tell, continue to advance over the next 10+ years. This is the reason I believe these trends will also hold for quite some time.
Growing Demand for Data: The demand for data as a product is skyrocketing with machine learners, data scientists, and others finding more and more applications. 4 years ago, data scientists and machine learning engineers in almost any company could be happy to get their hands on data as a byproduct, pulling it out from any place they could find. Now, more and more companies have 100s+ of data scientists & machine learning engineers and all of them need properly cared for data. Public APIs are exploding in usage. as are public and company internal data sets just for data science purposes.
Growing Mass of Data: The mass of available data, as well as devices that capture data is skyrocketing and seems to double every three years.
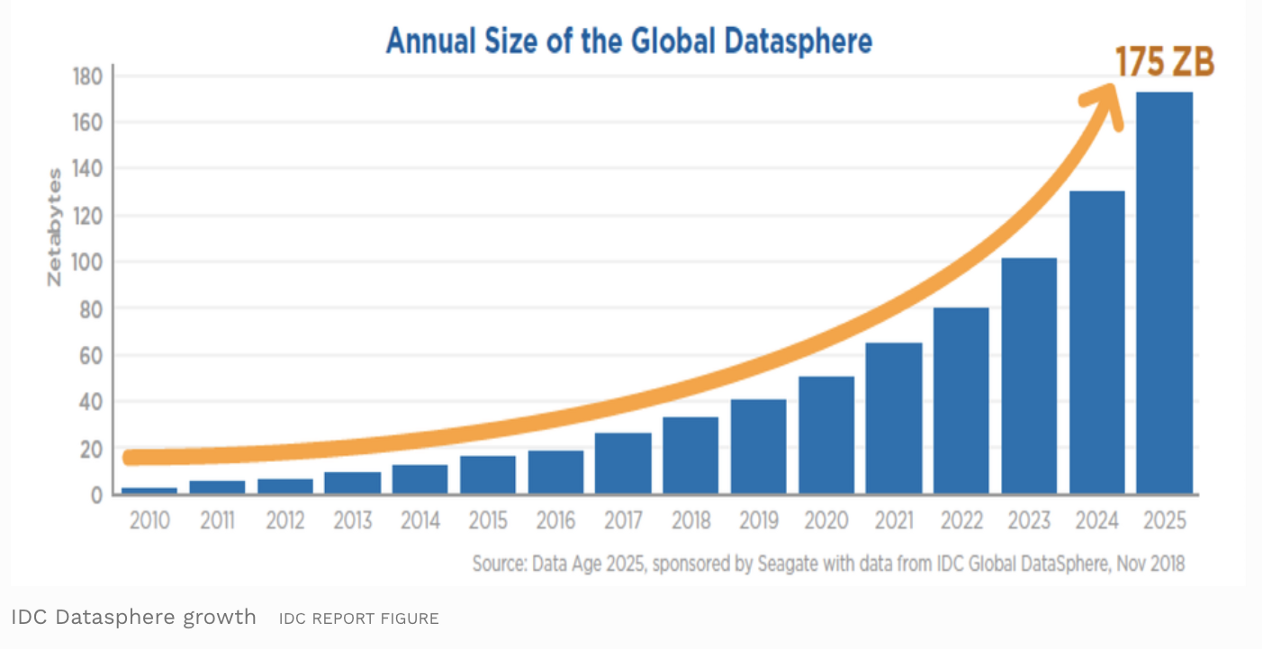
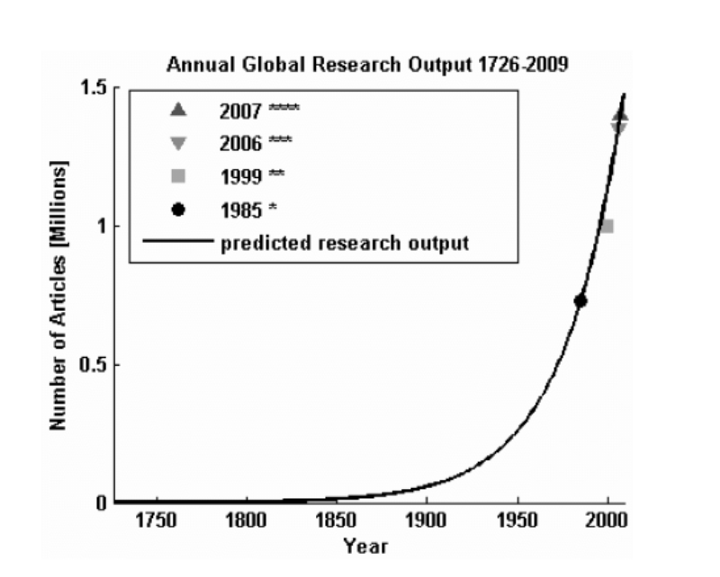
Growing Complexity in Markets: I do believe that markets and the competitive environments we work in become more and more complex as we make them so. Qualitative reasons for this are given for instance in the book “Edge: value-driven digital transformation”. I also like to believe that the growth of knowledge correlates with the complexity of the world, as such the exponential growth of academic papers might be another good point to see the growth of complexity.
All of those forces essentially produce a huge competitive advantage for companies mastering the art of crunching data and turn it into decisions & actions. Let’s explore the four trends that help to build up this competitive advantage in detail.
Trend No 1: Continuous Intelligence in Detail
Continuous intelligence is a possibility that exists now, and that did not exist before.
The possibility to make the cycle from data to decisions & actions continuous, not “one-time”!
Turns out, a basic “recommendation engine” that displays product recommendations to you on Amazon.com can react extremely quickly to changing user behavior or to the results of an A/B test. Those recommendation engines have already completed the circle from data to action into one continuous flow.
But this technology, in variations, can be applied to almost any kind of action and any kind of data. It may come in other forms like “decision support” or statistics, but it’s there.
In other companies, this cycle is just a linear one-time thing but in some, this already turned into a massive competitive advantage. Examples are Google in search, Amazon in recommendations, “wirkaufendeinauto.de” in pricing used cars, and many more.
The cycle of intelligence is the way that raw data created by actions is again transformed into new decisions & actions. It’s depicted by ThoughtWorks like this:
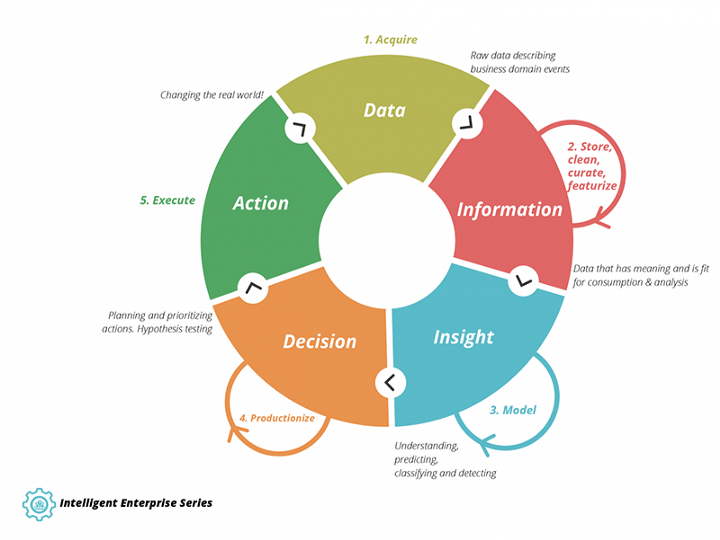
– What to do about this trend: Place your company on the Intelligence maturity model. Then think about for a minute where other companies in your industry are probably in this space. This really determines whether you are playing catchup, or could be able to secure a competitive advantage.
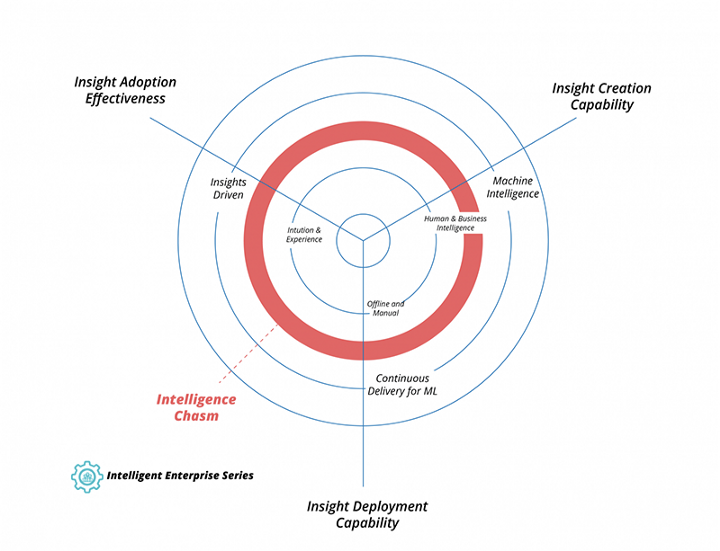
– Reason not to evaluate this trend: I don’t think there is a reason not to evaluate this trend. Continuous intelligence is already applied in industries where you wouldn’t suspect it, in hospitals, in industrial organizations to optimize machine throughput and find errors or breaking machines and all across the industry. As explained above, the data is growing exponentially, and with that the chance for other companies to disrupt yours. I do however think the timeframe for your company depends on your competitive environment though as well as your internals.
– Reason to consider other trends first: If you haven’t invested any efforts towards making data available in your company, don’t consider yourself data-driven or data-inspired, than you probably want to think about the other trends first.
– Further Ressources: ThoughtWorks provides great resources on this topic explaining particularly well how machine learning continuous cycles work, but also how decision support looks like.
Intelligence Enterprise Series by ThoughtWorks Part 1.
Intelligence Enterprise Series by ThoughtWorks Part 2.
Intelligence Enterprise Series by ThoughtWorks Part 3.
Trend No 2: DataOps in Detail
DataOps is the name of a trend that now has taken a proper form. It’s the trend of integrating both a product and thus a value perspective as well as the now best practices of software engineering to the usual data work.
This trend is driven by the DataOps manifesto, the companies dataKitchen & data bricks.
DataOps means we apply a DevOps mentality, companied with the usual method from lean manufacturing and an agile mindset to work with data. Key models include the idea of data & idea pipelines depicted below:
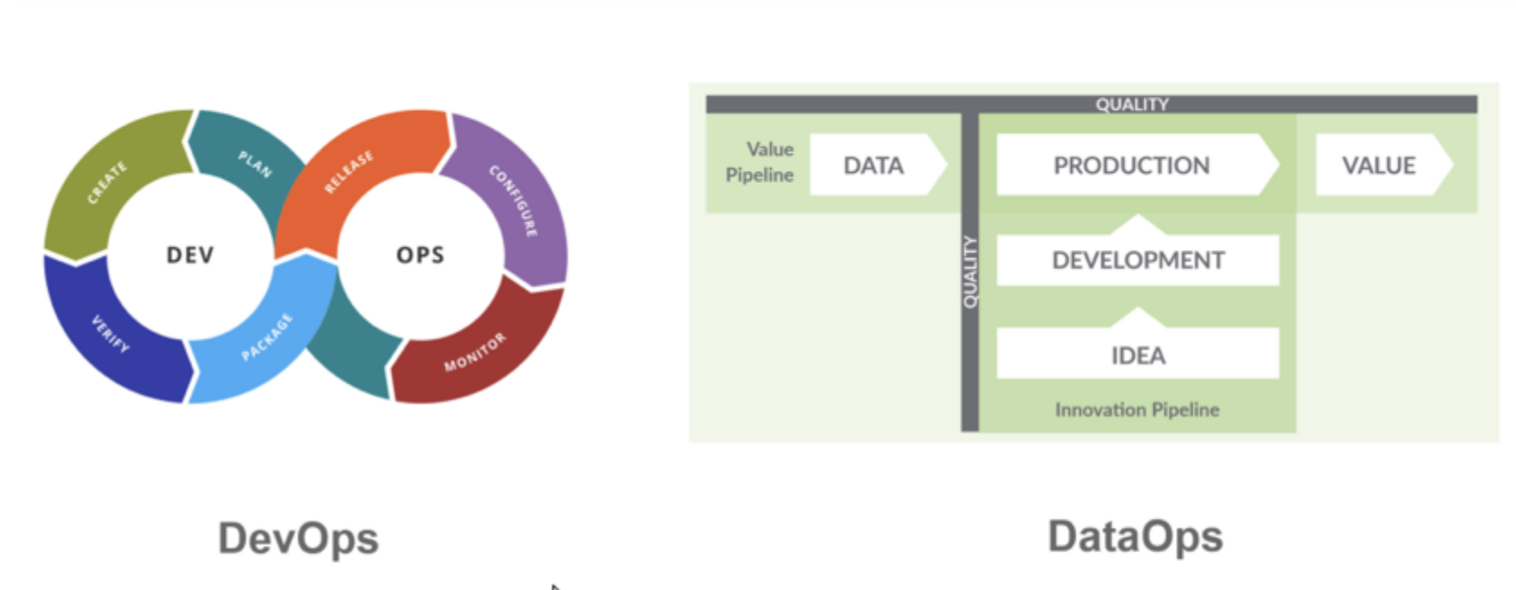
– Why is this so important now? All three forces squeeze data & analytics departments to focus on delivering value in a fast-changing environment. Really dataOps is only codifying what needs to be done to get that focus right.
– Reason to evaluate this trend: If your company & your competitive environment are growing more and more complex, your data world will follow.
– Reason to evaluate this trend: If your data & analytics teams are struggling to work in agile frameworks like SCRUM because they should. If you don’t have a product manager responsible for your analytics & data teams, because you should.
– Further resources: This trend hasn’t taken a systematic form, but some information is avilable which are the manifesto and some blog posts. Here are two of them:
DataOps Medium Blog post
DataOps Manifesto
Data Democratisation in Detail
Data democratization in one sentence means “give data access to everyone”. Companies like Airbnb, Zynga, eBay, and Facebook have been actively practicing data democratization for years now. There are a lot of pitfalls, and a lot to learn from those companies which is why I’ve already written about them:

– Why is this so important now? The growing complexity of the world means much more data is actually needed to make decisions. Without it, in a world of growing complexity, the other means of making decisions, gut feelings, will break sooner or later. The growing amount of data actually means there is a lot more data you have to give people access to.
– Reason to evaluate this trend: How many people in your company have access to data? 30% or less? Then you’re definitely below the threshold to act (Industry averages vary somewhere between 30–40%).
– Reason to not evaluate this trend: You have a large self-serve analytics setup? Direct SQL access or something comparable for most people in your company? Then there’s no reason to look deeper into this trend.
– Ressources:
One post from me on this topic.
Blog post explaining some of the reasons to move in this direction.
Data Mesh in Detail
DDD, microservices & DevOps changed the way we develop software in the last decade. Data in the analytics department, however, did not catch up to that. To speed up decision making based on data in a company with a modern development approach, analytics & software teams need to change.
(1) software teams must consider data a product they serve to everybody else, including analytics teams
(2) analytics teams must build on that, stop hoarding data and instead pull it in on-demand
(3) analytics teams must start to consider their data lakes/ data warehouses as data products as well.
A data mesh can look just like this:
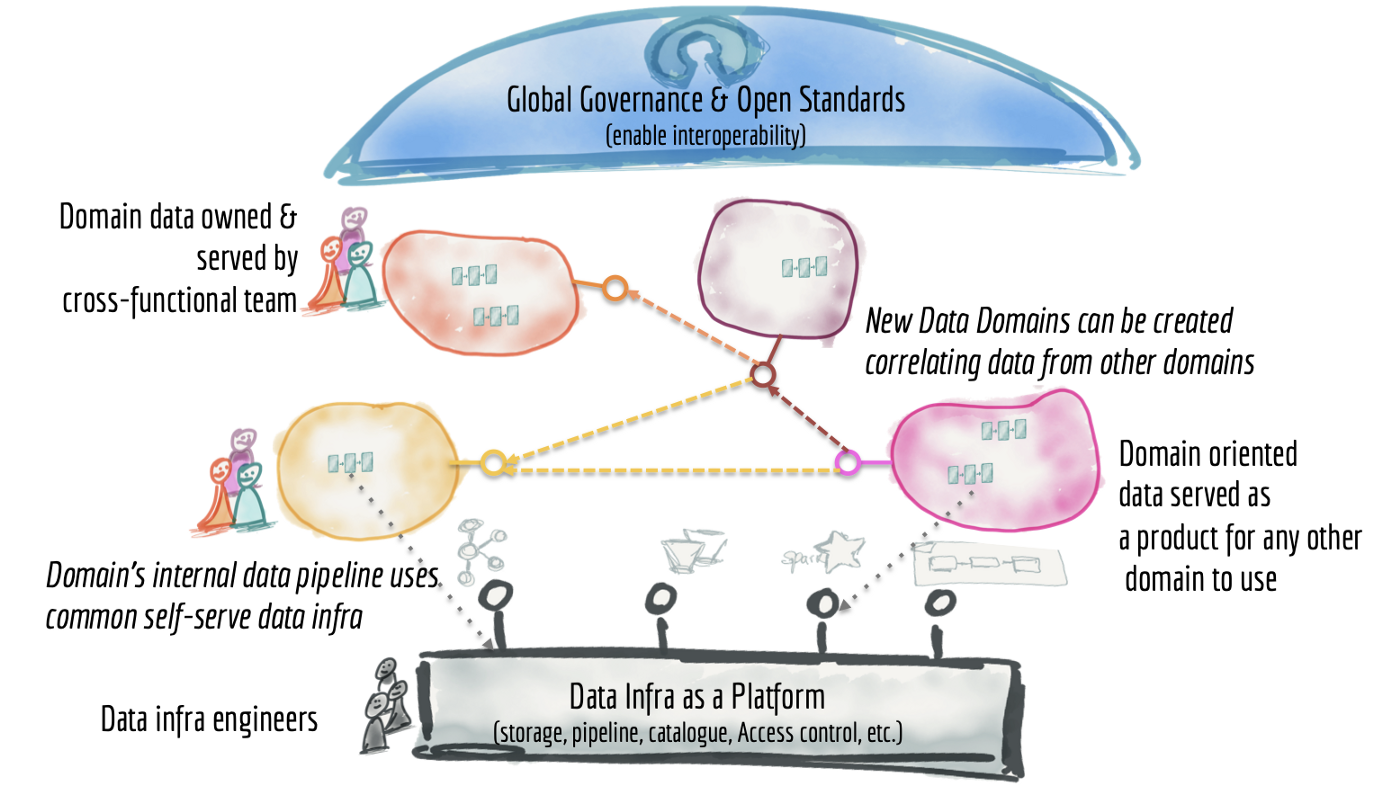
– Reasons to consider building a data mesh: Complex domains, large organizational structures, lots of data, and growing internal demand for data are all good reasons to consider this trend.
– Reasons not to consider data meshes: If you feel that your domains are still simple, easy enough to be managed by for instance one analytics department, then I don’t see a reason to switch to a data mesh. Just as microservices, data mesh are a trade-off between flexibility (which you gain with a data mesh) and complexity (which grows with a data mesh). If the complexity cost isn’t worth it, keep a central approach.
– Resources: The resource base on data meshes is constantly growing, I’d like to highlight three ones here.
The original data mesh article from Z. Dehghani, ThoughtWorks.
A more applied version I wrote on the topic.
The Zalando webinar explaining their version of a data mesh implemented together with ThoughtWorks.
Zalando explains their version of a data mesh.
—
Fuente: Sven Balnojan